



Practitioner’s guide for using Cassandra as a real-time feature store



By Alan Ho
The following document describes best practices for using Apache Cassandra® / DataStax AstraDB as a real-time feature store. The document covers primarily the performance and cost aspects of selecting a database for storing machine learning features. Real-Time AI requires a database that supports both high-throughput and low latency queries to serve features, as well as high write throughput for updating features. Under real world conditions, Cassandra can serve features for real-time inference with a tp99 < 23ms. Cassandra is used by large companies such as Uber and Netflix for their feature store.
This guide does not discuss the data science aspects of real-time machine learning, or the lifecycle management aspects of features in a feature store. The best practices we’ll cover are based on technical conversations with practitioners at large technology firms such as Google, Facebook, Uber, AirBnB, and Netflix on how they deliver real-time AI experiences to their customers on their cloud-native infrastructures. Although we’ll specifically focus on how to implement real-time feature storage with Cassandra, the architecture guidelines really apply to any database technology, including Redis, MongoDB, and Postgres.
What is real-time AI?
Real-time AI makes inferences or training models based on recent events. Traditionally, training models and inferences (predictions) based on models have been done in batch – typically overnight or periodically through the day. Today, modern machine learning systems perform inferences of the most recent data in order to provide the most accurate prediction possible. A small set of companies like TikTok and Google has pushed the real-time paradigm further by including on-the-fly training of models as new data comes in.
Because of these changes in inference, and changes that will likely happen to model training, persistence of feature data – data that is used to train and perform inferences for a ML model – needs to also adapt. When you’re done reading this guide, you’ll have a clearer picture of how Cassandra and DataStax Astra DB, a managed service built on Cassandra, meets real-time AI needs, and how they can be used in conjunction with other database technologies for model inference and training.
What’s a feature store?
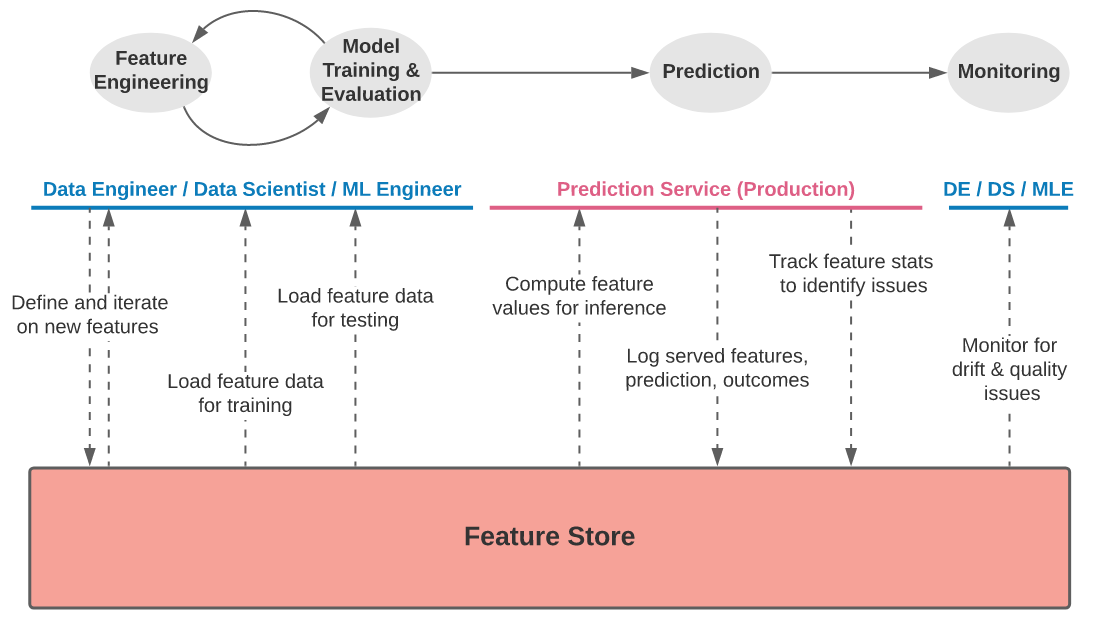
Life cycle of a feature store courtesy of the Feast blog
A feature store is a data system specific to machine learning (ML) that:
- Runs data pipelines that transform raw data into feature values
- Stores and manages the feature data itself, and
- Serves feature data consistently for training and inference purposes
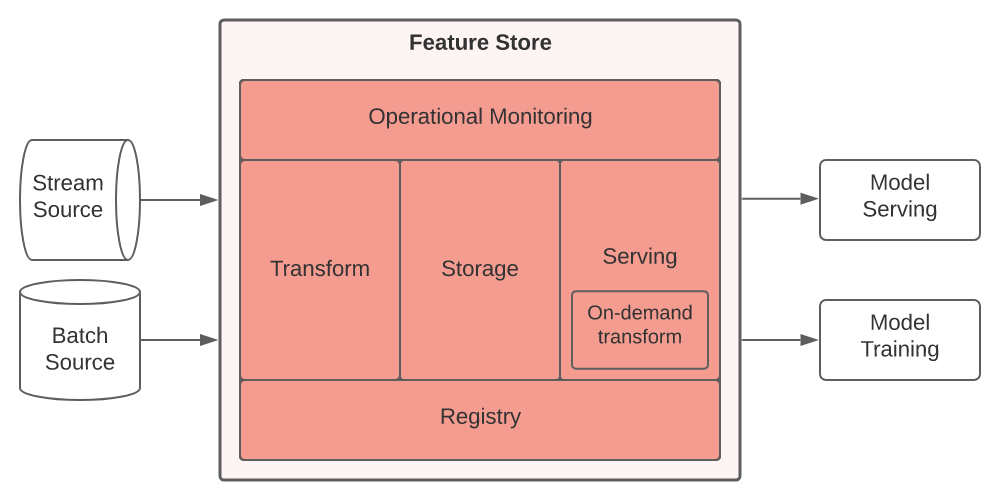
Main components of a feature store courtesy of the Feast blog
Real-time AI places specific demands on a feature store that Cassandra is uniquely qualified to fulfill, specifically when it comes to the storage and serving of features for model serving and model Training.
Best Practices
Implement low latency queries for feature serving

For real-time inference, features need to be returned to applications with low latency at scale. Typical models involve ~200 features spread across ~10 entities. Real-time inferences require time to be budgeted for collecting features, light-weight data transformations, and performing an inference. According to the following survey (also confirmed by our conversations with practitioners), feature stores need to return the features to an application performing inference in under 50ms.
Typically, models require “inner joins” across multiple logical entities – combining rows values from multiple tables that share a common value ; this presents a significant challenge to low-latency feature serving. Take the case of Uber Eats, which predicts the time to deliver a meal. Data needs to be joined from order information, which is joined with restaurant information, which is further joined by traffic information in the region of the restaurant. In this case, two inner joins are necessary (see the illustration below).
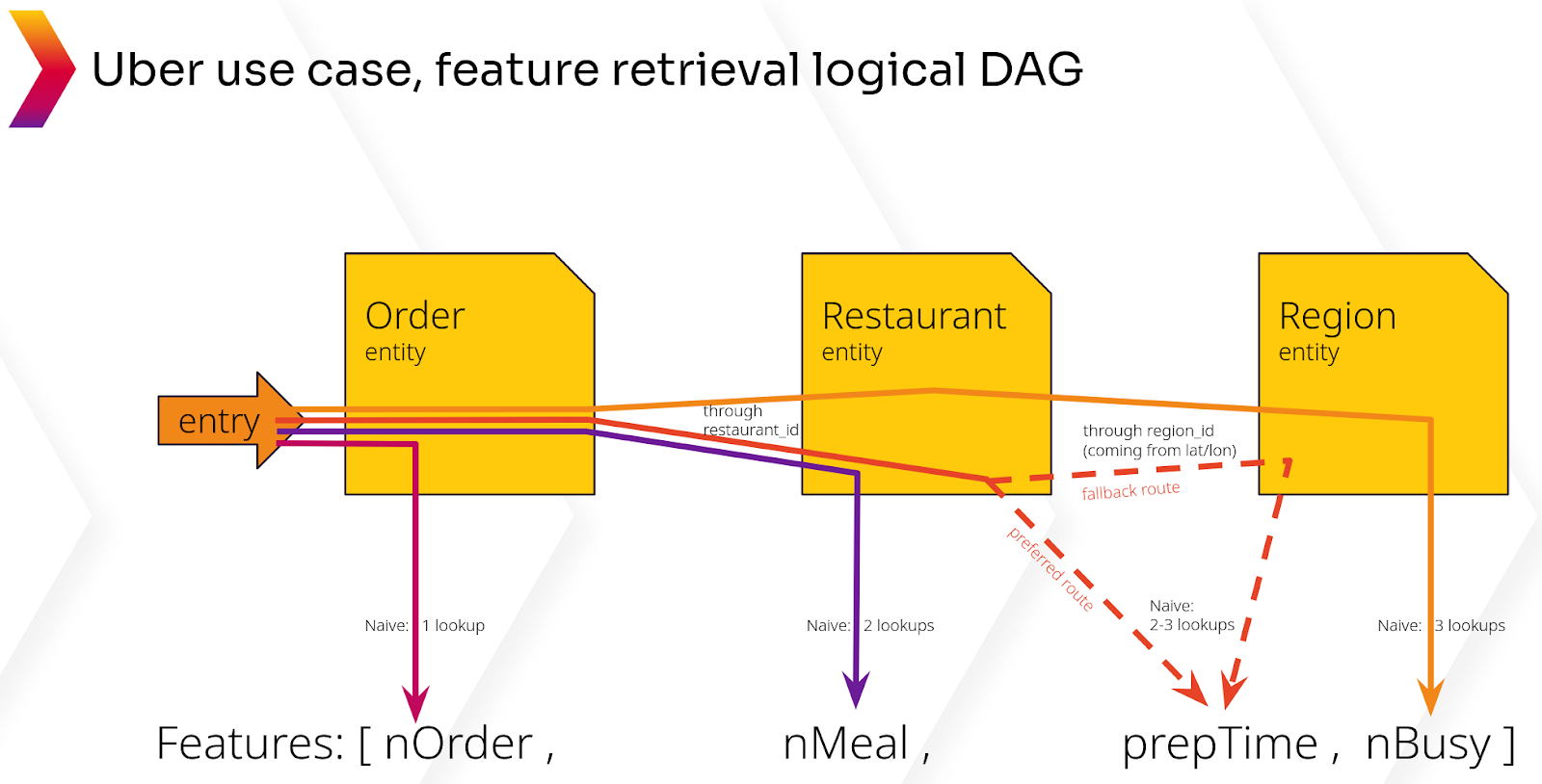
To achieve an inner join in Cassandra, one can either denormalize the data upon insertion or make 2 sequential queries to Cassandra + perform the join on the client side. Although it’s possible to perform all inner joins upon inserting data into the database through denormalization, having a 1:1 ratio between model and table is impractical because it means maintaining an inordinate number of denormalized tables. Best practices suggest that the feature store needs to allow for 1-2 sequential queries for inner joins, combined with denormalization.
Here is a summary of the performance metrics that can be used to estimate requirements for real-time ML pipelines:
- Testing Conditions:
- # features = 200
- # of tables (entities) = 3
- # inner join = 2
- Query TPS : 5000 queries / second
- Write TPS : 500 records / second
- Cluster Size : 3 nodes on AstraDB*
- Latency Performance summary (uncertainties here are standard deviations):
- tp95 = 13.2(+/-0.6) ms
- tp99 = 23.0(+/-3.5) ms
- tp99.9 = 63(+/- 5) ms
- Effect of compaction:
- tp95 = negligible
- tp99, tp999 = negligible, captured by the sigmas quoted above
- Effect of Change Data Capture (CDC):
- tp50, tp95 ~ 3-5 ms
- tp99 ~ 3 ms
- tp999 ~ negligible
* The following tests were done on DataStax’s Astra DB’s free tier, which is a serverless environment for Cassandra. Users should expect similar latency performance when deployed on 3 nodes using the following recommended settings.
The most significant impact on latency is the number of inner joins. If only one table is queried instead of three, the tp99 drops by 58%; for two tables, it is 29% less. The tp95 drops by 56% and 21% respectively. Because Cassandra is horizontally scalable, querying for more features does not significantly increase the average latency, either.
Lastly, if the latency requirements cannot be met out of box, Cassandra has two additional features: the ability to support denormalized data (and thus reduce inner joins) due to high write-throughput capabilities, and the ability to selectively replicate data to in-memory caches (e.g. Redis) through Change Data Capture. You can find more tips to reduce latency here.
Implement fault tolerant and low latency writes for feature transformations
A key component of real-time AI is the ability to use the most recent data for doing a model inference, so it is important that new data is available for inference as soon as possible. At the same time, for enterprise use cases, it is important that the writes are durable because data loss can cause significant production challenges.

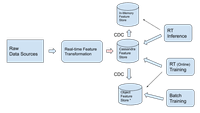
Suggested deployment architecture to enable low-latency feature transformation for inference
*Object store (e.g. S3 or HIVE) can be replaced with other types of batch oriented systems such as data warehouses.
There is a trade off between low latency durable writes and low latency feature serving. For example, it is possible to only store the data in a non-durable location (e.g. Redis), but production failures can make it difficult to recover the most up-to-date features because it would require a large recomputation from raw events.
A common architecture suggests writing features to an offline store (e.g. Hive / S3), and replication of the features to an online store (e.g. in-memory cache). Even though this provides durability and low latency for feature serving, it comes at the cost of introducing latency for feature writes, which invariably causes poorer prediction performance.
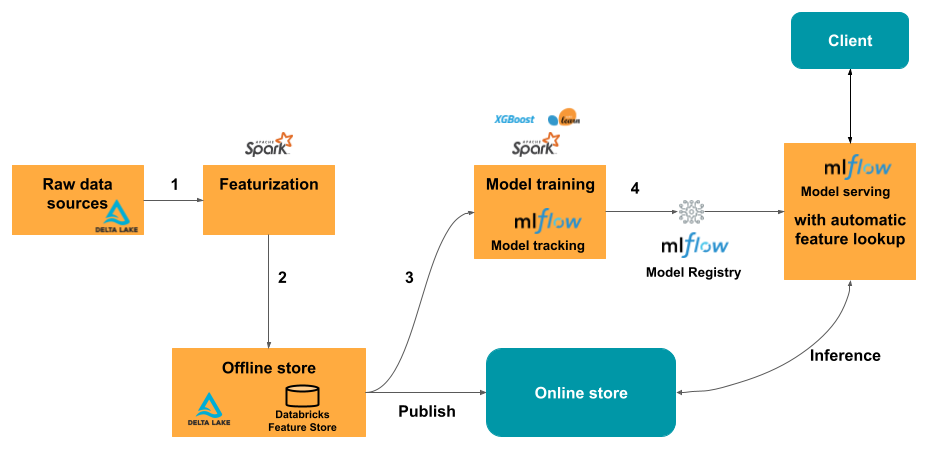
Databricks Reference Architecture for Real-time AI
Cassandra provides a good trade-off between low-latency feature serving and low-latency “durable” feature writes. Data written to Cassandra is typically replicated a minimum of three times, and it supports multi-region replication. The latency from writing to availability to read is typically sub-millisecond. As a result, by persisting features directly to the online store (Cassandra) and bypassing the offline store, the application has faster access to recent data to make more accurate predictions. At the same time, CDC from the online store to the offline store allows for batch training or data exploration with existing tools.
Implement low latency and writes for prediction caching and performance monitoring
In addition to storing feature transformation, there is also the need to store predictions and other tracking data for performance monitoring.
There are several use cases for storing predictions:
- Prediction store – In this scenario, a database used to cache predictions made by either a batch system or a streaming system. The streaming architecture is particularly useful when the time it takes to inference is beyond what is acceptable in a request-response system.
- Prediction performance monitoring It is often necessary to monitor the prediction output of a real-time inference and compare to the final results. This means having a database to log the results of the prediction and the final result.
Cassandra is a suitable store for both use cases because of its high-write throughput capabilities.
Plan for elastic read and write workloads
The level of query and write transactions per second usually depends on the number of users simultaneously using the system. As a result, workloads may change based on the time of day or time of year. Having the ability to quickly scale up and scale down the cluster to support increased workloads is important. Cassandra and Astra DB have features that enable dynamic cluster scaling.
The second aspect that could affect write workloads is if there are changes in the feature transformation logic. With a large spike in write workloads, Cassandra automatically prioritizes maintaining low-latency queries and write TPS over data consistency, which is typically acceptable for performing real-time inference.
Implement low-latency, multi-region support
As real-time AI becomes ubiquitous across all apps, it’s important to make sure that feature data is available as close as possible to where inference occurs. This means having the feature store in the same region as the application doing inference. Replicating the data in the feature store across regions helps ensure that feature. Furthermore, replicating just the features rather than the raw data used to generate the features significantly cuts down on cloud egress fees.
Astra DB supports multi-region replication out of the box, with a replication latency in the milliseconds. Our recommendation is to stream all the raw event data to a single region, perform the feature generation, and store and replicate the features to all other regions.
Although theoretically one can achieve some latency advantage by generating features in each region, event data often needs to be joined with raw event data from other regions;. from a correctness and efficiency standpoint, it is easier to ship all events to one region for processing for most use-cases. On the other hand, if the model usage makes the most sense in a regional context, and most events are associated with region-specific entities, then it makes sense to treat features as region specific. Any events that do need to be replicated across regions can be placed in keyspaces with global replication strategies, but ideally this should be a small subset of events. At a certain point, replicating event tables globally will be less efficient than simply shipping all events to a single region for feature computations.
Plan for cost-effective and low-latency multi-cloud support
Multi-cloud support increases the resilience of applications, and allows customers to negotiate lower prices. Single-cloud online stores such as DynamoDB result in both increased latency for retrieving features and significant data egress costs, but also creates lockin to a single cloud vendor.
Open source databases that support replication across clouds provide the best balance of performance cost. To minimize the cost of egress, events and feature generation should be consolidated into one cloud, and feature data should be replicated to open source databases across the other clouds. This minimizes egress costs.
Plan for both batch and real-time training of production models
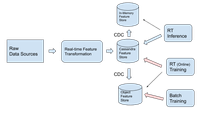
Suggested deployment architecture to enable low-latency feature transformation for inference
Batch processing infrastructure for building models is used for two use cases: building and testing new models, and building models for production. Therefore it was typically sufficient for feature data to be stored in slower object stores for the purpose of training. However, newer model training paradigms include updating the models in real-time or near real-time (real-time training); this is known as “online learning” (e.g. TikTok’s Monolith). The access pattern for real-time training sits somewhere between inference and traditional batch training. The throughput data requirements are higher than inference (because it is not usually accessing a single-row lookup), but not as high as batch processing that would involve full table scans.
Cassandra can support a TPS rating in the hundreds of thousands per second (with an appropriate data model), which can provide enough throughput for most real time training use cases. However in the case the user wants to keep real time training from an object store, Cassandra achieves this through CDC to object storage. For batch training, CDC should replicate data to object storage. It’s worth noting that machine learning frameworks like Tensorflow and PyTorch are particularly optimized for parallel training of ML models from object storage.
For a more detailed explanation of “online learning”, see Chip Huyuen’s explanation on Continual Learning, or this technical paper from Gomes et. al.
Support for Kappa architecture
Kappa architecture is gradually replacing Lambda architecture due to costs and data quality issues due to online/offline skew. Although lots of articles discuss the advantages of moving from separate batch and real-time computation layers to a single real-time layer, articles don’t often describe how to architect the serving layer.
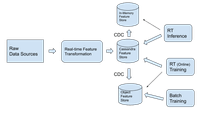
Using Kappa architecture for generating features brings up some new considerations:
- Updating features are being updated en masse and can result in a significant number of writes to the database. It’s important to ensure that query latency does not suffer during these large updates.
- The serving layer still needs to support different types of queries, including low-latency queries for inference, and highTPS queries for batch training of models.
Cassandra supports Kappa architecture in the following ways:
- Cassandra is designed for writes; an increased influx of writes does not significantly reduce the latency of queries. Cassandra opts for processing the writes with eventual consistency instead of strong consistency, which is typically acceptable for making predictions.
- Using CDC, data can be replicated to object storage for training and in-memory storage for inference. CDC has little impact on the latency of queries to Cassandra.
Support for Lambda architecture
Most companies have a Lambda architecture, with a batch layer pipeline that’s separate from the real-time pipeline. There are several categories of features in this scenario:
- Features that are only computed in real time, and replicated to the batch feature store for training
- Features that are only computed in batch, and are replicated to the real-time feature store
- Features are computed in real-time first, then recomputed in the batch. Discrepancies are then updated in both the real-time and object store.
In this scenario, however, DataStax recommends the architecture as described in this illustration:
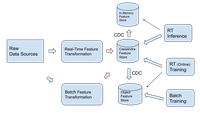
The reasons are the following:
- Cassandra is designed to take batch uploads of data with little impact on read latency
- By having a single system of record, data management becomes significantly easier than if the data is split between the feature store and object store. This is especially important for features that are first computed realtime, then recomputed in batch.
- When exporting data from Cassandra via CDC to the object feature store, the data export can be optimized for batch training (a common pattern used at companies like Facebook), which significantly cuts down on training infrastructure costs.
If it is not possible to update existing pipelines, or there are specific reasons that the features need to be in the object store first, our recommendation is to go with a two-way CDC path between the Cassandra feature store and and the object store, as illustrated below.
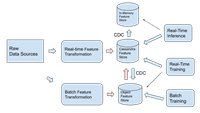
Ensure compatibility with existing ML software ecosystem
To use Cassandra as a feature store, it should be integrated with two portions of the ecosystem: machine learning libraries that perform inference and training, and data processing libraries that perform feature transformation.
The two most popular frameworks for machine learning are TensorFlow and PyTorch. Cassandra has Python drivers that enable easy retrieval of features from the Cassandra database; in other words, multiple features can be fetched in parallel (see this example code). The two most popular frameworks for performing feature transformation are Flink and Spark Structured Streaming. Connectors for both Flink and Spark are available for Cassandra. Practitioners can use tutorials for Flink and Spark Structured Streaming and Cassandra.
Open Source feature stores such as FEAST also have a connector and tutorial for Cassandra as well.
Understand query patterns and throughput to determine costs
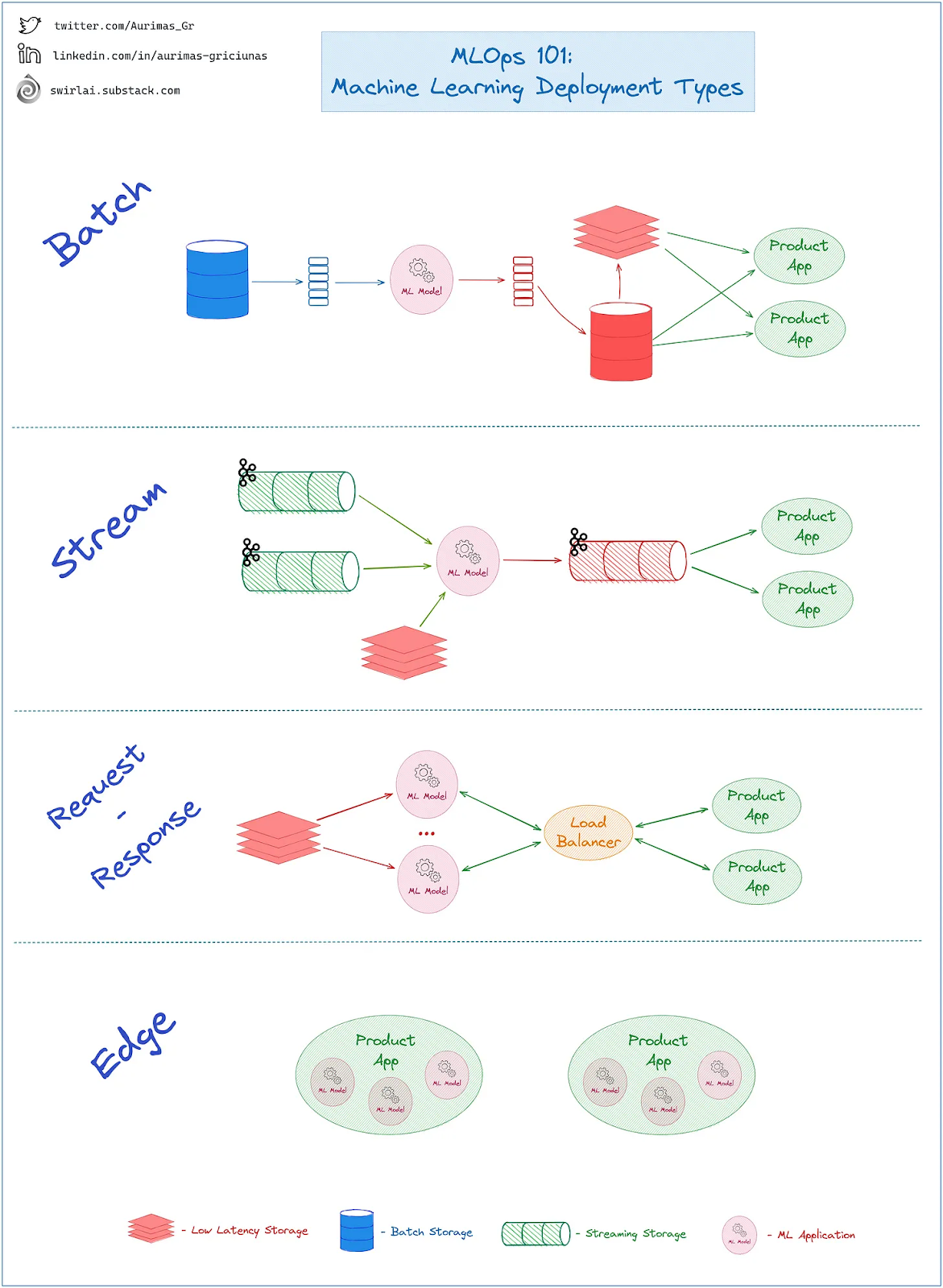
Various models of real-time inference courtesy of Swirl.ai
The number of read queries for Cassandra as a feature store is dependent on the number of incoming inference requests. Assuming the feature data is split across multiple tables, or if the data can be loaded in parallel, this should give an estimate of the fanout between real-time inference can be made. For example 200 features across 10 entities in 10 separate tables gives you about a 1:10 ratio between real-time inference and queries to Cassandra.
Calculating the number of inferences being performed will depend on the inference traffic pattern. For example in the case of “streaming inference,” an inference will be performed whenever a relevant feature changes, so the total number of inferences is dependent on how often the feature data changes. When inference is performed in a “request-reply” setting, it’s is only being performed when a user requests it.
Understand batch and realtime write patterns to determine costs
The write throughput is primarily dominated by how frequently the features change. If denormalization occurs, this too could impact the number of features that are written. Other write throughput considerations include caching inferences for either batch or streaming inference scenarios.
Conclusion
When designing a real-time ML pipeline, special attention needs to be paid to the performance and scalability of the feature store. The requirements are particularly well satisfied by NoSQL databases such as Cassandra. Stand up your own feature store with Cassandra or AstraDB and try out the Feast.dev with the Cassandra connector.


