






Short description about Apache Cassandra

Apache Cassandra is a highly scalable, high-performance distributed database designed to handle large amounts of data across many commodity servers, providing high availability with no single point of failure. It is a type of NoSQL database. Let us first understand what a NoSQL database does.
Moving to questions and answers:
1. What is Apache Cassandra?
Answer: Apache Cassandra is a highly scalable, high-performance distributed database designed to handle large amounts of data across many commodity servers, providing high availability with no single point of failure. It is a type of NoSQL database. Let us first understand what a NoSQL database does.
2. What are the key features of any NoSQL Database?
Answer:

3. What are the different types of NoSQL Databases?
Answer: There are majorly 4 types of NoSQL Databases,
- Key-Value Store
- Document Store
- Column Store
- Graph Databases
4. What is a NoSQL Database?
Answer:
- NoSQL is also referred as Not only SQL to emphasize that they may support SQL-like query language used in relational database.
- NoSQL database provides a mechanism to store and retrieve data, which are modeled rather than the tabular relations used in Relational databases.
5. What is Document Store DB? Explain with an example.
Answer:
The data record is the JSON/XML representation of key-value pairs. Every record can have a different set of fields.
Document DBs are similar to Key-value pairs, But the difference is that the key is associated with a document

6. What is Graph DB? Explain with an example.
Answer:

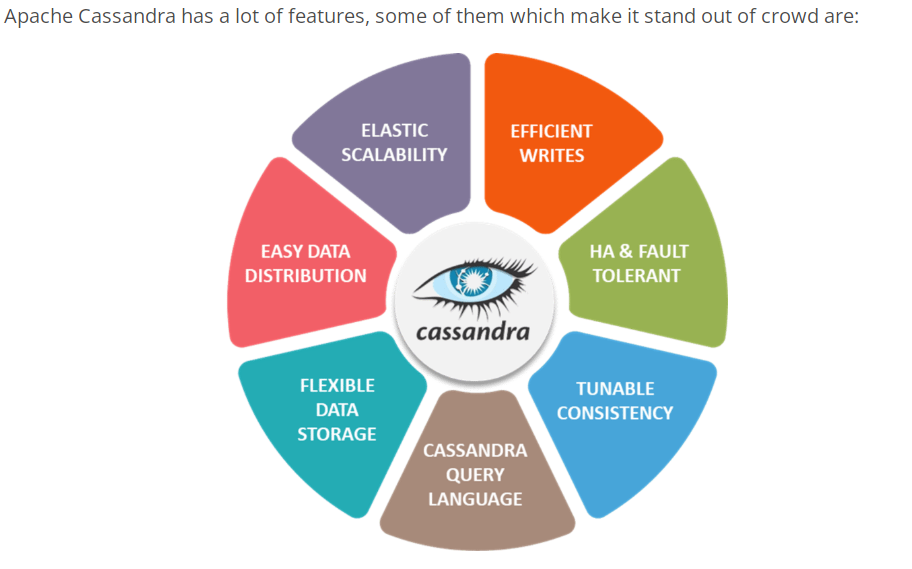
7. What are the features of Apache Cassandra?
Answer:
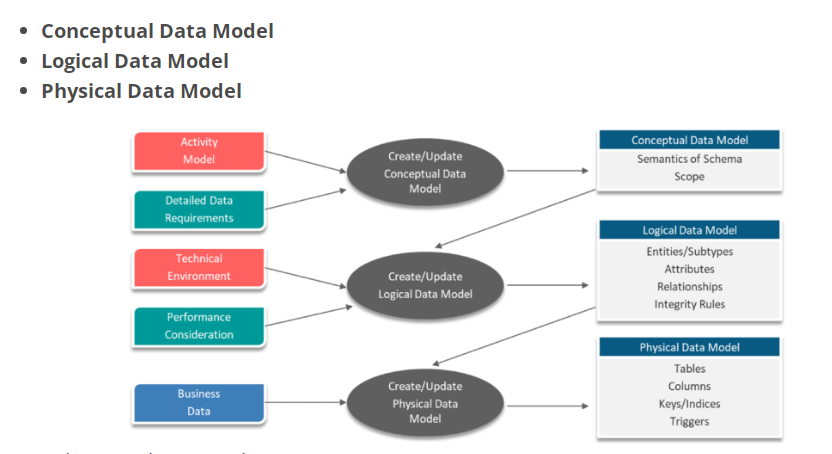
8. What are the Different Types of Data models?
Answer:
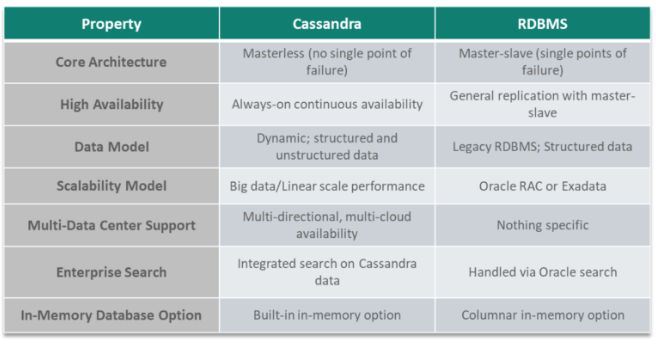
9. What are the Key Differences between Cassandra and Traditional RDBMS?
Answer:
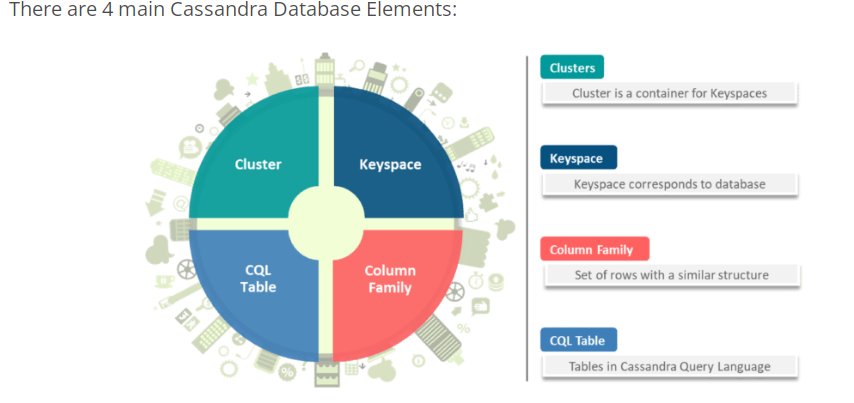
10. What are the different Database Elements of Cassandra?
Answer:
11. What is CQLSH? And why is it used?
Answer:
Cassandra-Cqlsh is a query language that enables users to communicate with its database. By using Cassandra cqlsh, you can do following things:
- Define a schema
- Insert a data, and
- Execute a query
12. What are Clusters in Cassandra?
Answer:
The outermost structure in Cassandra is the cluster. A cluster is a container for Keyspaces
Sometimes called the ring, because Cassandra assigns data to nodes in the cluster by arranging them in a ring
A node holds a replica for a different range of data.
13. What is a Keyspace in Cassandra?
Answer: A keyspace is an outermost container for data in Cassandra. Like a relational database, a keyspace has a name and a set of attributes that define keyspace-wide behavior. The keyspace is used to group Column families together.
14. What are durable writes?
Answer: Durable Writes provides a means to instruct Cassandra whether to use the commit log for updates on the current KeySpace or not.
This option is not mandatory. The default value for durable writes is TRUE.
15. Differentiate between Drop and Truncate in CQLSH
Answer:
- The Drop table command drops the specified table including all the data from the keyspace.
- The Truncate table command is used to truncate a table and deletes all the rows of the table permanently.
16. Differentiate between Static and Dynamic CQL Tables.
Answer:
- A Static Table uses a relatively static set of column names and is similar to Relational Database Table.
- A dynamic table allows you to pre-compute result sets and stores them in a single row for efficient data retrieval.
17. How is a Keyspace created in Cassandra? & What are the parameters used?
Answer:
CREATE KEYSPACE ABC
WITH replication = { ‘class ’: ‘SimpleStrategy’, ‘replication_factor’: ‘3’}
AND durable_writes = ‘TRUE’;
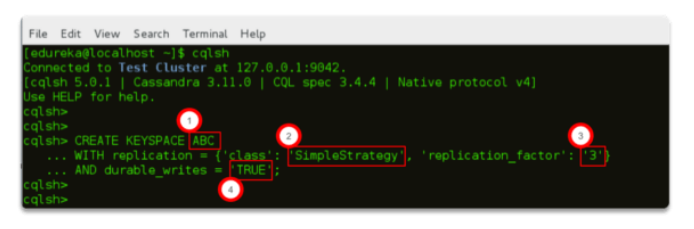
The parameters used while creating a keyspace are:
Keyspace Name
Replication Strategy
Replication Factor &
Durable Writes
18. What do you mean by replication factor?
Answer: Cassandra stores copies (called replicas) of each row based on the row key. The replication factor refers to the number of nodes that will act as copies (replicas) of each row of data.
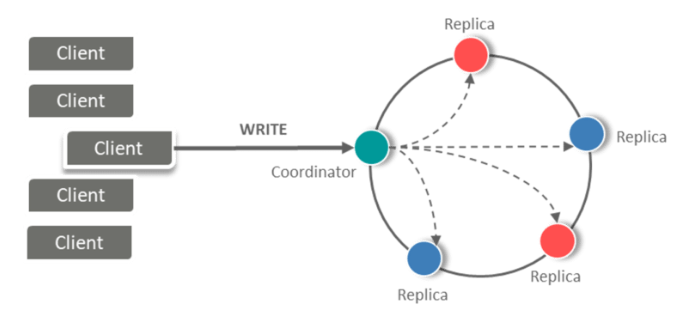
19. What do you mean by replication Strategy?
Answer: The replica placement strategy refers to how the replicas will be placed in the ring
There are different strategies that ship with Cassandra for determining which nodes will get copies of which keys
There are mainly two types of Strategies:
- Simple Strategy
- Network Topology Strategy
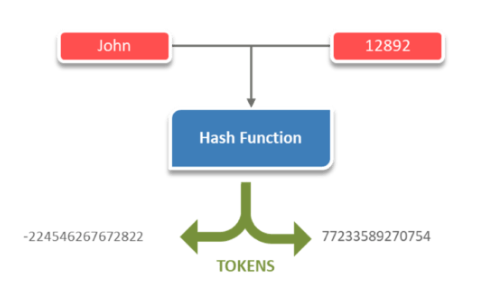
20. What are partitions and Tokens in Cassandra?
Answer:
Partition: It is a hash function located on each node that hashes tokens from designated values in rows being added. It converts a variable-length input to a fixed-length value.
Token: Integer value generated by a hashing algorithm, identifying a partition’s location within a cluster
21. What are the different types of Partitioners in Cassandra? Explain.
Answer:
- Murmur3Partitioner is the default partitioner. It is both improved and faster than RandomPartitioner. Uniformly distributes data based on the MurmurHash function.
64-bit hash value partition key with Range: 263 to 263-1 - RandomPartitioner was the default partitioner prior to Cassandra 1.2. It is used with vnodes. It has a Uniform Distribution.It uses MD5 hash values with Range: 0 to 2127-1
- ByteOrderedPartioner is used for ordered partitioning. It orders rows lexically by key bytes. Using the ordered partitioner allows ordered scans by primary key. This means we can scan rows as though we were moving a cursor through a traditional index.
22. What do you mean by Snitch?
Answer: A snitch determines which datacenters and racks, nodes belong to. They inform Cassandra about the network topology and allow Cassandra to distribute replicas specifically, the Replication strategy places the replicas based on the information provided by the new snitch.
23. Name a few snitches
Answer: There are many types of snitches, such as
- Dynamic snitching
- SimpleSnitch
- RackInferringSnitch
- Ec2Snitch
- PropertyFileSnitch
- GossipingPropertyFile
- Ec2MultiRegionSnitch
- GoogleCloudSnitch
- CloudstackSnitch
24. Explain the terms Memtable, CommitLog and SSTables.
Answer:
Commit log: The Commit log is a crash-recovery mechanism that supports Cassandra’s durability goals
MemTable: MemTable is an in-memory data structure that corresponds to a CQL table
SSTable: The contents of the memtable are flushed to disk in a file called an SSTable.
25. What is the use of Coordinator Node in Read?
Answer: Read Operation is easy because clients can connect to any node in the cluster to perform reads. If a client connects to a node that doesn’t have the data it’s trying to read, the node it’s connected to will act as the coordinator node.
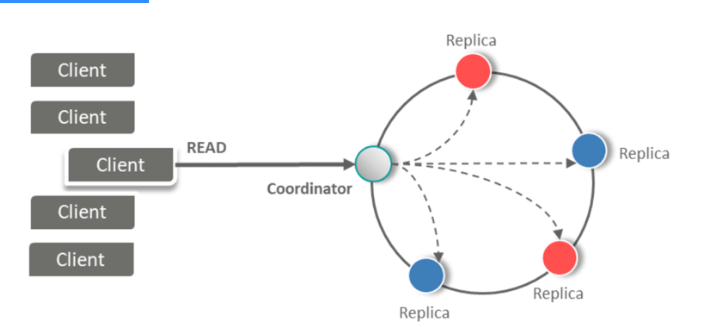
26. How does Cassandra perform Read operation? Explain
Answer:
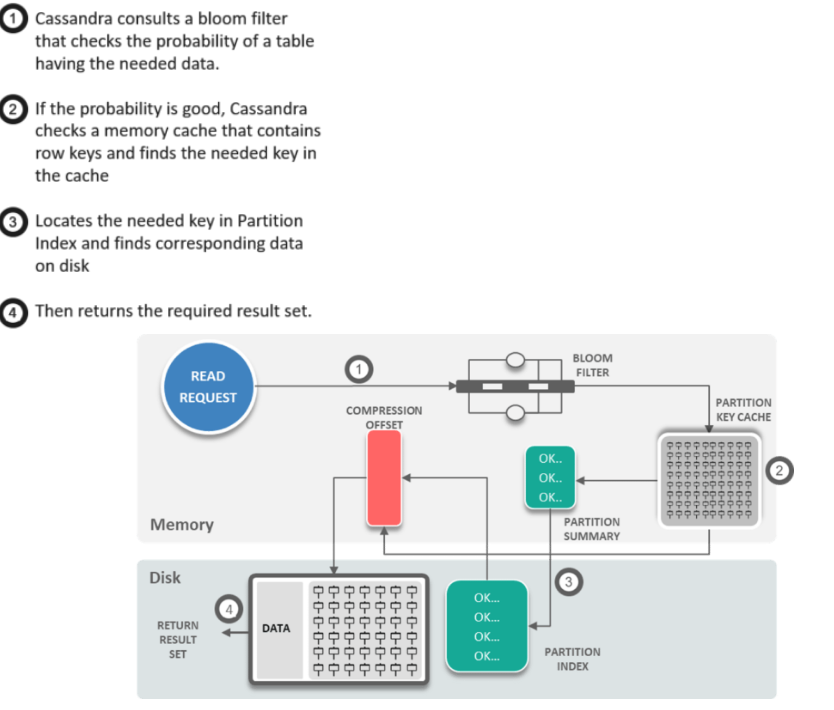
27. What is Anti-Entropy and How is it associated with Merkel Tree?
Answer: Anti-entropy is the replica synchronization mechanism, ensuring that data on different nodes is updated to the newest version
Cassandra uses Merkle tree for anti-entropy repair. A Merkel Tree is a hash tree where leaves are hashes of the values of individual keys.
28. What do you mean by Compaction?
Answer: It is the process of freeing up space by merging largely accumulated datafiles. It improves performance by reducing the number of required seeks.
29. What is Hinted Handoff?
Answer: Hinted Handoff is a mechanism to ensure availability, fault-tolerance and graceful degradation in Cassandra. The node that receives the hint will know when the unavailable node comes back online again, because of Gossip.
30. Explain Nodetool Utility.
Answer: The Nodetool Utility is a command-line utility that comes out of the box with Cassandra and is a great tool for administration and monitoring. It communicates with JMX to perform operational and monitoring tasks exposed by MBeans.
31. What is Python Stress test in Cassandra?
Answer: Cassandra comes with a popular utility called py_stress that can be used to run a stress test on Cassandra cluster. The Cassandra-stress tool is a Java-based stress testing utility for basic benchmarking and load testing a Cassandra cluster. This is an effective tool for populating a cluster and stress testing CQL tables and queries.
32. What are Roles in CQLSH?
Answer: Roles enable authorization management on a larger scale than security per user can provide. A role is created and may be granted to other roles. Hierarchical sets of permissions can be created with the help of it.
33. Explain the different Logging levels in Cassandra.
Answer:
- ALL: All levels including custom levels
- TRACE: Designates finer-grained informational events than the DEBUG
- DEBUG: Designates fine-grained informational events that are most useful to debug an application
- INFO: Designates informational messages that highlight the progress at a coarse-grained level
- ARN: Designates potentially harmful situations
- ERROR: Designates error events that might still allow the application to continue running
- OFF: The highest possible rank and is intended to turn off logging
34. What do you understand by composite type?
Answer: Composite Type is a cool feature of Hector and Cassandra.
It allow to define a key or a column name with a concatenation of data of different type.
With CassanraUnit, you can use CompositeType in 2 places :
- row key
- column name
35. What do you understand by Node in Cassandra?
Answer: Node is the place where data is stored.
36. What do you understand by Commit log in Cassandra?
Answer: Commit log is a crash-recovery mechanism in Cassandra. Every write operation is written to the commit log.
37. What do you understand by SSTabl in Cassandra?
Answer: SSTable is a disk file to which the data is flushed from the mem-table when its contents reach a threshold value.
38. What do you understand by Bloom filter in Cassandra?
Answer: Bloom filter are nothing but quick, nondeterministic, algorithms for testing whether an element is a member of a set. It is a special kind of cache. Bloom filters are accessed after every query.
39. What do you understand by Column Family?
Answer: Column family is a container for an ordered collection of rows. Each row, in turn, is an ordered collection of columns.
40. What is the use of “ResultSet execute(Statement statement)” method?
Answer: This method is used to execute a query. It requires a statement object.
41. What are the collection data types provided by CQL?
Answer:
List : A list is a collection of one or more ordered elements.
Map : A map is a collection of key-value pairs.
Set : A set is a collection of one or more elements.
42. Explain Zero Consistency?
Answer: In this write operations will be handled in the background, asynchronously. It is the fastest way to write data, and the one that is used to offer the least confidence that operations will succeed.
43. What are secondary indexes?
Answer: Secondary indexes are indexes built over column values. In other words, let’s say you have a user table, which contains a user’s email. The primary index would be the user ID, so if you wanted to access a particular user’s email, you could look them up by their ID. However, to solve the inverse query given an email, fetch the user ID requires a secondary index.
44. When to avoid secondary indexes?
Answer: Try not using secondary indexes on columns contain a high count of unique values and that will produce few results.
45. What ports does Cassandra use?
Answer: By default, Cassandra uses 7000 for cluster communication, 9160 for clients (Thrift), and 8080 for JMX. These are all editable in the configuration file or bin/cassandra.in.sh (for JVM options). All ports are TCP.
46. What do you understand by High availability?
Answer: A high availability system is the one that is ready to serve any request at any time. High avaliability is usually achieved by adding redundancies. So, if one part fails, the other part of the system can serve the request. To a client, it seems as if everything worked fine.
47. What do you understand by Snitches?
Answer: A snitch determines which data centers and racks nodes belong to. They inform Cassandra about the network topology so that requests are routed efficiently and allows Cassandra to distribute replicas by grouping machines into data centers and racks. Specifically, the replication strategy places the replicas based on the information provided by the new snitch. All nodes must return to the same rack and data center. Cassandra does its best not to have more than one replica on the same rack.
48. What is Hector?
Answer: Hector is an open source project written in Java using the MIT license. It was one of the early Cassandra clients and is used in production at Outbrain. It wraps Thrift and offers JMX, connection pooling, and failover.
49. Explain Cassandra data model?
Answer: The Cassandra data model has 4 main concepts which are cluster, keyspace, column, column family.
Clusters contain many nodes(machines) and can contain multiple keyspaces.
- A keyspace is a namespace to group multiple column families, typically one per application.
- A column contains a name, value and timestamp.
- A column family contains multiple columns referenced by a row keys.
50. What do you understand by Mem-table in Cassandra?
Answers: Mem-table is a memory-resident data structure. After the commit log, the data will be written to the mem-table. Sometimes, for a single-column family, there will be multiple mem-tables.


















