






If you are Uber and you need to store the location data that is sent out every 30 seconds by both driver and rider apps, what do you do? That’s a lot of real-time data that needs to be used in real-time.
Uber’s solution is comprehensive. They built their own system that runs Cassandra on top of Mesos. It’s all explained in a good talk by Abhishek Verma, Software Engineer at Uber: Cassandra on Mesos Across Multiple Datacenters at Uber (slides).
Is this something you should do too? That’s an interesting thought that comes to mind when listening to Abhishek’s talk.
Developers have a lot of difficult choices to make these days. Should we go all in on the cloud? Which one? Isn’t it too expensive? Do we worry about lock-in? Or should we try to have it both ways and craft brew a hybrid architecture? Or should we just do it all ourselves for fear of being cloud shamed by our board for not reaching 50 percent gross margins?
Uber decided to build their own. Or rather they decided to weld together their own system by fusing together two very capable open source components. What was needed was a way to make Cassandra and Mesos work together, and that’s what Uber built.
For Uber the decision is not all that hard. They are very well financed and have access to the top talent and resources needed to create, maintain, and update these kind of complex systems.
Since Uber’s goal is for transportation to have 99.99% availability for everyone, everywhere, it really makes sense to want to be able to control your costs as you scale to infinity and beyond.
But as you listen to the talk you realize the staggering effort that goes into making these kind of systems. Is this really something your average shop can do? No, not really. Keep this in mind if you are one of those cloud deniers who want everyone to build all their own code on top of the barest of bare metals.
Trading money for time is often a good deal. Trading money for skill is often absolutely necessary.
Given Uber’s goal of reliability, where out of 10,000 requests only one can fail, they need to run out of multiple datacenters. Since Cassandra is proven to handle huge loads and works across datacenters, it makes sense as the database choice.
And if you want to make transportation reliable for everyone, everywhere, you need to use your resources efficiently. That’s the idea behind using a datacenter OS like Mesos. By statistically multiplexing services on the same machines you need 30% fewer machines, which saves money. Mesos was chosen because at the time Mesos was the only product proven to work with cluster sizes of 10s of thousands of machines, which was an Uber requirement. Uber does things in the large.
What were some of the more interesting findings?
-
You can run stateful services in containers. Uber found there was hardly any difference, 5-10% overhead, between running Cassandra on bare metal versus running Cassandra in a container managed by Mesos.
-
Performance is good: mean read latency: 13 ms and write latency: 25 ms, and P99s look good.
-
For their largest clusters they are able to support more than a million writes/sec and ~100k reads/sec.
-
Agility is more important than performance. With this kind of architecture what Uber gets is agility. It’s very easy to create and run workloads across clusters.
Here’s my gloss of the talk:
In the Beginning
-
Statically partitioned machines across different services.
-
50 machines might be dedicated to the API, 50 for storage, etc, and they did not overlap.
In the Now
-
Want run everything on Mesos, including stateful services like Cassandra and Kafka.
-
Mesos is Data Center OS that allows you to program against your datacenter like it’s a single pool of resources.
-
At the time Mesos was proven to run on 10s of thousands of machines, which was one of Uber’s requirements, so that’s why they chose Mesos. Today Kubernetes could probably work too.
-
Uber has build their own sharded database on top of MySQL, called Schemaless. The idea is Cassandra and Schemaless will be the two data storage options in Uber. Existing Riak installations will be moved to Cassandra.
-
-
A single machine can run services of different kinds.
-
Statistically multiplexing services on the same machine can lead to needing 30% fewer machines. This is a finding from an experiment run at Google on Borg.
-
If, for example, one services uses a lot of CPU it matches well with a service that uses a lot of storage or memory, then these two services can be efficiently run on the same server. Machine utilization goes up.
-
Uber has about 20 Cassandra clusters now and plans on having 100 in the future.
-
Agility is more important than performance. You need to be able manage these clusters and perform different operations on them in a smooth manner.
-
Why run Cassandra in a container and not just on the whole machine?
-
You want to store hundreds of gigabytes of data, but you also want it replicated on multiple machines and also across datacenters.
-
You also want resource isolation and performance isolation across different clusters.
-
It’s very hard to get all that in a single shared cluster. If you, for example, made a 1000 node Cassandra cluster it would not scale or it would also have performance interference across different clusters.
-
In Production
-
~20 clusters replicating across two data centers (west and east coast)
-
Originally had 4 clusters, including China, but since merging with Didi those clusters were shut down.
-
~300 machine across two data centers
-
Largest 2 clusters: more than a million writes/sec and ~100k reads/sec
-
One of the clusters is storing the location that is sent out every 30 seconds by both the driver and rider apps.
-
-
Mean read latency: 13 ms and write latency: 25 ms
-
Mostly use LOCAL_QUORUM consistency level (which means strong consistency)
Mesos Backgrounder
-
Mesos abstracts CPU, memory, and storage away from machines.
-
You are not looking at individual machines, you are looking at and programming to a pool of resources.
-
Linear scalability. Can run on 10s of thousands of machines.
-
Highly available. Zookeeper is used for leader election amongst a configurable number of replicas.
-
Can launch Docker containers or Mesos containers.
-
Pluggable resource isolation. Cgroups memory and CPU isolator for Linux. There’s a Posix isolator. There are different isolation mechanisms for different OSes.
-
Two level scheduler. Resources from Mesos agents are offered to different frameworks. Frameworks schedule their own tasks on top of these offers.
Apache Cassandra Backgrounder
-
Cassandra is a good fit for uses cases at Uber.
-
Horizontally scalable. Reads and writes scale linearly as new nodes are added.
-
Highly available. Fault tolerance with tunable consistency levels.
-
Low latency. Getting sub millisecond latencies within the same datacenter.
-
Operationally simple. It’s a homogenous cluster. There’s no master. There are no special nodes in the cluster.
-
Sufficiently rich data model. It has columns, composite keys, counters, secondary indexes, etc
-
Good integration with open source software. Hadoop, Spark, Hive all have connectors to talk to Cassandra.
Mesosphere + Uber + Cassandra = dcos-cassandra-service
-
Uber worked with Mesosphere to produce mesosphere/dcos-cassandra-service - an automated service that makes it easy to deploy and manage on Mesosphere DC/OS.
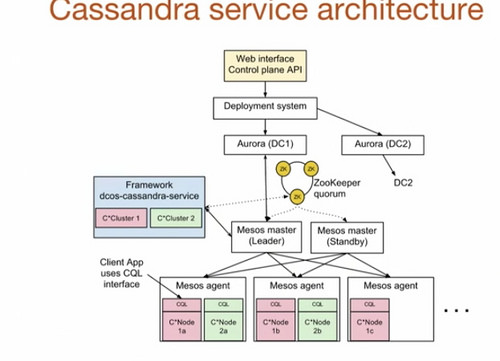
-
At the top is the Web Interface or the Control Plane API. You specify how many nodes you want; how many CPUs you want; specify a Cassandra configuration; then submit it to the Control Plane API.
-
Using the deployment system at Uber it launches on top of Aurora, which is used to run stateless services, it’s used to bootstrap the dcos-cassandra-service framework.
-
In the example the dcos-cassandra-service framework has two clusters that talk to a Mesos master. Uber uses five Mesos masters in their system. Zookeeper is used for leader election.
-
Zookeeper is also used to store framework metadata: which tasks are running, Cassandra configurations, health of the cluster, etc.
-
Mesos agents run on every machine in the cluster. The agents provide the resources to the Mesos master and the master doles them out in discrete offers. Offers can be either accepted or rejected by the framework. Multiple Cassandra nodes could run on the same machine.
-
Mesos containers are used, not Docker.
-
Override 5 ports in configuration (storage_port, ssl_storage_port, native_transport_port, rpcs_port, jmx_port) so multiple containers can be run on the same machine.
-
Persistent volumes are used so data is stored outside the sandbox directory. In case Cassandra fails the data is still in the persistent volume and is offered to the same task if it crashes and restarts.
-
Dynamic reservation is used to make sure resources are available to relaunch a failed task.
-
-
Cassandra Service Operations
-
Cassandra has an idea of a seed node that bootstraps the gossip process for new nodes joining the cluster. A custom seed provider was created to launch Cassandra nodes which allows Cassandra nodes to be rolled out automatically in the Mesos cluster.
-
The number nodes in a Cassandra cluster can be increased using a REST request. It will start the additional nodes, give it the seed nodes, and bootstraps additional Cassandra daemons.
-
All Cassandra configuration parameters can be changed.
-
Using the API a dead node can be replaced.
-
Repair is needed to synchronize data across replicas. Repairs are on the primary key range on a node-by-node basis. This approach does not affect performance.
-
Cleanup removes data that is not needed. If nodes have been added then data will be moved to the new nodes so cleanup is required to delete the moved data.
-
Multi-datacenter replication is configurable through the framework.
-
-
Multi-datacenter support
-
Independent installations of Mesos are setup in each datacenter.
-
Independent instances of the framework are setup in each datacenter.
-
The frameworks talk to each other and periodically exchange seeds.
-
That’s all that is needed for Cassandra. By bootstrapping the seeds of the other datacenter the nodes can gossip the topology and figure out what the nodes are.
-
Round trip ping latency between data centers is 77.8 ms.
-
The asynchronous replication latency for P50 : 44.69 ms; P95: 46.38ms; P99: 47.44 ms;
-
-
Scheduler Execution
-
The scheduler execution is abstracted into plans, phases, and blocks. A scheduling plan has different phases in it and a phase has multiple blocks.
-
The first phase a scheduler goes through when it comes up is reconciliation. It will go out to Mesos and figure out what’s already running.
-
There’s a deployment phase that checks if the number of nodes in the configuration are already present in the cluster and deploy them if necessary.
-
A block appears to be a Cassandra node specification.
-
There are other phases: backup, restore, cleanup, and repair, depending on which REST endpoints are hit.
-
-
Clusters can be started at a rate of one new node per minute.
-
Want to get to 30/seconds per node startup time.
-
Multiple nodes can not be started concurrently in Cassandra.
-
Usually give 2TB of disk space and 128GB of RAM are given to each Mesos node. 100GB is allocated for each container and 32GB of heap is allocated for each Cassandra process. (note: this was not clear, so may have the details wrong)
-
The G1 garbage collector is used instead of CMS, it has much better 99.9th percentile latency (16x) and performance without any tuning.
-
Bare Metal vs Mesos Managed Clusters
-
What is the performance overhead of using containers? Bare metal means Cassandra is not running in a container.
-
Read latency. There’s hardly any difference: 5-10% overhead.
-
On bare metal on average was .38 ms versus .44 ms on Mesos.
-
At P99 bare metal was .91 ms and on Mesos P99 is .98 ms.
-
-
Read throughput. Very little difference.
-
Write latency.
-
On bare metal on average was .43 ms versus .48 ms on Mesos.
-
At P99 bare metal was 1.05 ms and on Mesos P99 is 1.26 ms.
-
-
Write throughput. Very little difference.
Related Articles
-
Google On Latency Tolerant Systems: Making A Predictable Whole Out Of Unpredictable Parts
-
Google: Taming The Long Latency Tail - When More Machines Equals Worse Results
-
Google's Transition From Single Datacenter, To Failover, To A Native Multihomed Architecture
-
Uber Goes Unconventional: Using Driver Phones As A Backup Datacenter
-
Making The Case For Building Scalable Stateful Services In The Modern Era
-
4 Unique Ways Uber, Twitter, PayPal, and Hubspot Use Apache Mesos
















